Álhírek gyártóira általában olyan nyomorultakként szokás tekinteni, akiknek nincs az életben fontosabb szakmai kihívása, mint hogy a társadalom moráljának kárára könnyen kapható pénzhez jussanak. Az álhíreket még viszonylag gyorsan, de idővel egyre nehezebben lehet majd felismerni, és nincs tuti recept, legfeljebb a klasszikus út, hogy megbízható oldalakra hallgatunk, a többire pedig feltételesen.
Így amikor az a hír ment körbe a szerkesztőségek belső hírfolyamában, hogy Larry Page és Steve Jobs 2010-ben megegyeztek, hogy a Google 9 milliárd dollárért felvásárolja az Apple-t, az simán vállrándításra adhatott volna okot. A fenti mondatban máris legalább három marhaság van, és ebből csak az egyik az összeg nagysága, mégis:
a hír a Dow Jones hírfolyamáról érkezett. A befektetőket etette ezzel a híres pénzügyi hírszolgáltató.
A hamis hírt aztán eltávolították a rendszerből, és elnézést kérve
technikai hibára hivatkoztak.
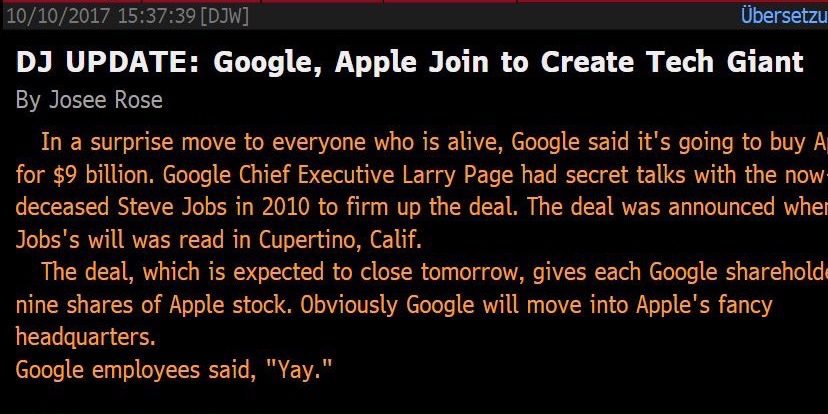
Fogalmam sincs, hogyan lehetne ez technikai hiba. Nem az történt, hogy elírták a 90 milliárdot 9-re, hanem itt van egy összefüggő angol szöveg, aminek a megfogalmazása ugyan erősen iskolapad-ízű, mégis érthető, feldolgozható, egy csínytevésnek tűnik inkább, nem technikai hibának.
Történt még egy dolog az eset után: az Apple-részvények azonnal megindultak felfelé, a 156 dolláron nyugvó szintről egyből 158-ra ugrottak, mielőtt korrigáltak volna - a hír eltűnése után - az eredeti értékre.
Valószínű, hogy a Dow Jones-nál egy ember tehet erről az esetről, és ezt ügyetlenül, vagy jobb híján hívják tehnikai hibának. Van azonban egy olyan lehetőség is, ami alapján még akár igaz is lehet a technikai malőr magyarázata: ha a cikket egy algoritmus írta, egy MI, amit a pénzügyi gyorshírek összeállítására készítettek. A jövőkutatások szerint már nincs messze az idő, amikor alap fogalmazási és hírszerkesztési munkákat mesterséges intelligenciák is elvégezhetnek, és biztosak lehetünk benne, hogy ebben a percben is valahol, valakik szövegeket csiholtatnak ki ilyen szoftverekből. Az pedig, hogy a szoftvert élesben engedik rá a rendszerre, valóban technikai malőr.
Az eset után a részvények árfolyamemelkedése pedig - na, találjátok ki - szintén algoritmusok eredménye, amik emberi beavatkozás nélkül cselekedtek, hiszen egyrészt a reakció gyorsasága, másrészt a tökéletesen hihetetlen hír sima beszopása is azt mutatja, hogy itt hülyerobotok álltak a háttérben.
Szóval még az is lehet, hogy már a robotok szívatnak robotokat, algoritmusok algoritmusokat, ami eléggé ijesztő, ha belegondolunk.
szucsadam
2016.07.10. 10:23
Címkék: photos algoritmus
A WWDC-n Craig "Szemöldök" Federighi bejelentette az Advanced Computer Vision ficsört az iOS-es Photos appban.
Ez csak részben jelent arcfelismerést, bár az is nagyon jó kis cucc: ezentúl aszerint válogathatunk a képek között, hogy az algoritmus szerint ki szerepel rajta. Ősrégi képesség egyébként, még az OS X-es iPhoto is tudta, de gondolom azóta fejlettebb technológiát alkalmaztak. És iOS-re.

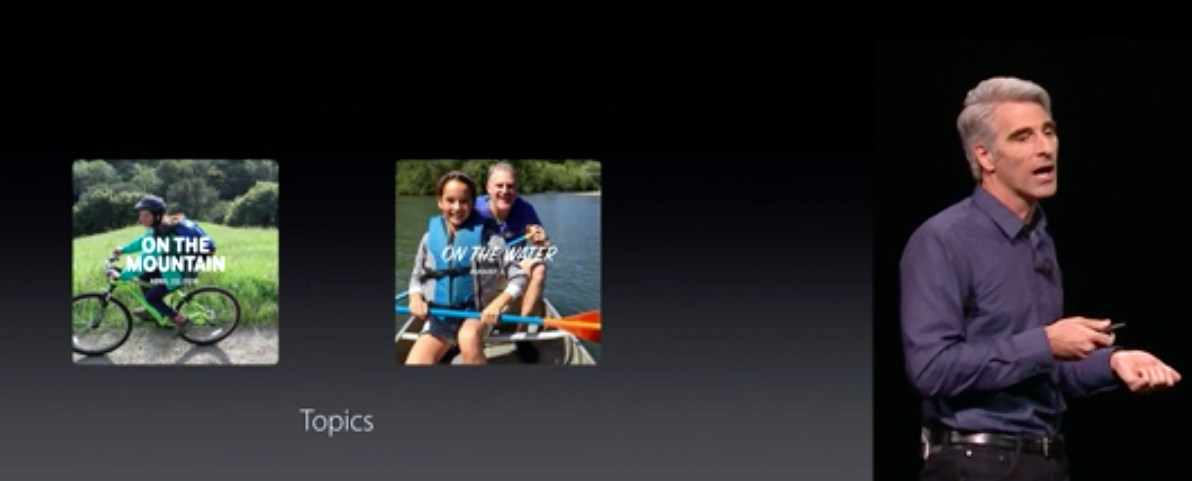
Az Advanced Computer Vision kiterjed azonban objektumokra is. A rendszer felismeri például a fenti képen, hogy ló szerepel rajta, víz, és hegy - állította Craig. Hogy ez miért jó? Egyrészt könnyebb lesz keresni a képeink között, ha tudjuk, mi szerepelt rajta. Másrészt a Memories nevű fülön, iOS 10-ben találhatunk topikokra szűrt összeállításokat: amikor a tengerparton voltunk, amikor a hegyekben kirándultunk, ésatöbbi.
Az Apple vezetője elárulta, hogy képenként 11 milliárd számítást végez el az iOS. 11 milliárd számítás alapján határozza meg, mit is láthatunk a képen. És ami nagyon fontos: ezeket a számításokat a telefonunk végzi el, ami egyrészt rossz, mert picit meríti az akksit, másrészt jó, mert nem veszik ki a kezünkből a saját képeinket, hogy aztán egy nagy üstben mindenféle kísérleteket végezzenek velük. Az Apple más fotókon fejlesztette ki az algoritmusait - szólt az állítás. És hát az iPhone-nak nincs is szüksége arra, hogy lepasszolja a labdát valamiféle szentséges szervernek. Elmúltak azok az idők, amikor a számítási kapacitás hiányára foghatták az ilyen megoldásokat: mára már mindenki tudja, hogy ez inkább a saját adataink jogainak részleges átruházásáról szól egy külső szolgáltató felé.
Ami fontos: ez most az első lépés. Itt látható, hogy áll most az objektumfelismerés máshol:
Dense captioning of Boston Dynamics Atlas Robot from Gene Kogan on Vimeo.
Lenyűgöző, de látszik, hogy a videós elemzésekben még sok a hiba, és ha motoros túrákra keresünk majd a Photosban, simán lehet, hogy egy hasraesett robot fotóját dobja fel a rendszer. De az biztos, hogy az algoritmus fejlődik majd, akár a Sirivel karöltve tudnák fejleszteni saját magukat, és egy idő után már a videók elemzése is jöhet. Izgalmas lesz látni, milyen apróságokat is megtalál majd a szoftver a képeink között. A saját eszközünkön, saját magunknak.
szucsadam
2013.08.24. 11:47
Címkék: algoritmus app store
A Fisku piackutató cég mutatott rá, hogy már nem csak a letöltésszám jelent előnyt a toplistákon. A legalább négy csillagra értékelt appok július végén elkezdtek emelkedni a ranglétrán, anélkül hogy a letöltésszámban bármilyen erre utaló folyamat lezajlott volna. Közelebbi vizsgálódás után kiderült, hogy a jelenség az értékeléssel van összefüggésben: a háromnál kevesebb csillagra értékelt programok egyre rosszabb helyeket csíptek meg.
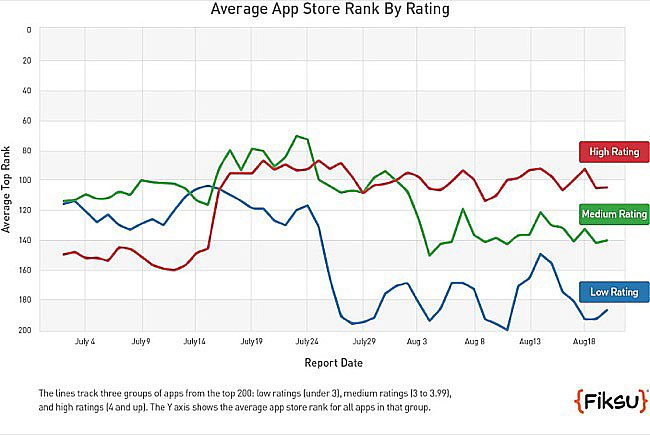
Ráadásul az is kiderült, hogy az eddigi 15 perces frissítés helyett három órára váltott az update-gyakoriság, nem tudni, hogy az új algoritmus miatt hagynak maguknak időt az elemzésre, vagy most már ez lesz a gyakorlat.
A felhasználó értékelések egyébként országonként változnak, ugyanarra a programra Magyarországon (20)...
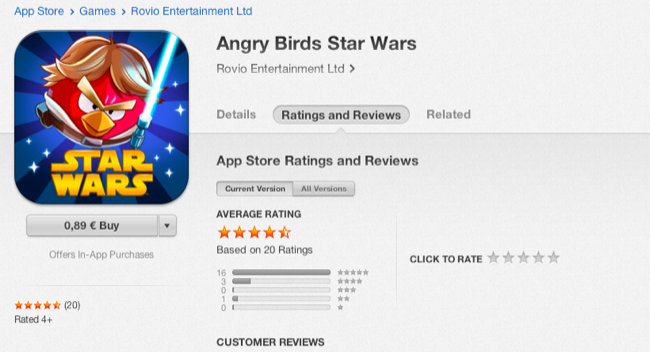
...sokkal kevesebb szavazat jön, mint mondjuk az USA-ban (2451).
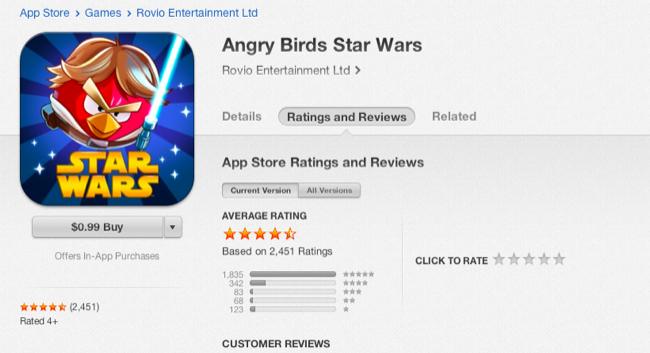
Ettől függetlenül biztos vagyok benne, hogy elfogadható mennyiségű pénzért meg lehet bízni embereket a hamis értékelésekkel. Akár világszerte megemelhető így az app helyezése. És nehéz lesz becsületesen játszani, ha már mindenki csal. Reméljük az Apple arra is fejlesztett algoritmust, hogy a hamis szavazókat kiszűrje.
Egyébként tavaly év közepén kezdett el okosodni az App Store találati listája is. Ha rákerestünk egy kifejezésre az online üzletben, 2012 júniusa előtt leginkább a névazonosság alapján dobta ki a találatokat a program. Azután a letöltésszámot is nézni kezdte: fontos lett, hányan töltötték le az appodat. A releváns szavakat is tudta már értelmezni, olyan kifejezéseket, amik egyébként nem szerepelnek a névben.
